
Notes from Jack Clark's Lecture at Oxford
Anthropic's co-founder on recursive self-improvement by 2028, inside Anthropic's ecosystem, claude as his personal therapist, and the irrationality of human kindness.

On Wednesday the 20th of May 2026, there was a buzz at the Schwarzman Centre of the University of Oxford. Jack Clark (co-founder of Anthropic, Head of Public Benefit and leading the new Anthropic Institute) was here to speak. The queue outside the Sohmen hall was long when I arrived, and before I’d even made it through the door, someone thrust a Pause AI leaflet into my hand. In the queue, I got chatting to an ex-history teacher who was building an EdTech startup on the side, and I sat down next to a delightful Aussie girl from Harvard Kennedy visiting a friend here. I had a sore throat so it was painfully uncomfortable to discuss AI policy with her whilst scoffing down my water to get each word in edgeways. The mic tap saved me and the crowd went silent.
Clark opened with a slide: Explore the future, or retreat from the present?

I sensed the direction that this was going to go, and glanced at the PauseAI leaflet in my Claude tote bag. Yeah I guess I see why they handed it to me, I must’ve seemed like an AGI-pilled twat. I ended up meeting with some people at PauseAI at EAG London the week after and have many thoughts (but that’s it’s own piece). Clark went on to explain that his talk would rest on the assumption that AI will succeed, and by success he meant recursive self improvement. Recursive self improvement is the idea that AI will succeed at building powerful systems that build better versions of themselves.


He asked the crowd if they knew what the Epoch Capabilities Index was, and was surprised by the number of hands that were raised. I was not surprised considering the selection of folk that turn up to this type of event, or are on the corners of the internet where they’d hear about it, but the bubble size is hard to estimate. He explained how we try and use benchmarks to understand and compare the capabilities of different AI models over time, and he pulled up a timeline of the underlying capabilities captured by the benchmark and what they mean. For example, solving Olympiad geometry at gold-medal standard in 2024, to Mythos exposing severe flaws in software in 2026 (and a bunch of different mathsy benchmarks in the middle).

The point he was pushing was that the models’ performance is improving proportional to the resources being pumped into them, and there is strong evidence of progress so far and therefore progress in the future. So what does continued success look like, and what are the implications? Clark warns about immense change on unimaginable magnitude, and expects the rates of model progress to compound on themselves to reach self-built models within 2-3 years. I’ll give it to him that he set up his arguments and claims in a way where this felt very plausible. I mean as Aschenbrenner said: That doesn’t require believing in sci-fi; it just requires believing in straight lines on a graph.
But then the question is, why do we keep developing the models and helping them progress if we don’t fully understand the implications, and we see the potential risks? Clark surprised me by admitting that if it were possible to elegantly slow down the development of AI, that would be net good. However he says that given the commercial and geopolitical rivalries currently, we are very unlikely to be able to pull together collective action for AI, and subsequently very unlikely to achieve a global slowdown.
This feels analogous to a climate collective action problem, but I’m still not convinced. Climate is hard because emissions are diffuse, invisible, and the costs of cutting them are immediate while the benefits are distant. Compute is measurable, concentrated in a handful of fabs and data centres, and there are already people whose entire job is counting FLOPs. Why can’t we have regulations like limiting to 10^25 FLOP ?
I’m uncertain as to whether the arms race framing is a genuine constraint or a story we’ve collectively decided to tell ourselves because the alternative feels like we’d be leaving the benefits that come with development on the table. The prisoner’s dilemma logic assumes the payoffs are fixed, that being first to AGI is unambiguously good for the actor who gets there. If the risks are as serious as Clark and others believe, then the payoff matrix looks different and ideally we don’t want to be defecting into a world-ending system? I worry that the existential risk framing is something policymakers hold intellectually but not in the part of the brain that makes resource allocation decisions.1
Clark then zooms in from AI’s broader capabilities from the index, to the evolution of AI’s capabilities in his own personal life and use cases, calling it his “personal telescope”. He cracks a joke about how Claude helps him manage his stress, especially as the co-founder of a company like Anthropic, whose work could potential lead to the end of humanity. The crowd laughed, mildly nervously. Despite this objectively being a scary thought for him to admit out loud, I did find it endearing just how self-deprecatingly British he was about all of this, which I think we need a little more of given how American the faces of the frontier labs are.
Clark split his use cases into his work, and his interpersonal relationships and life advice.
Regarding his work, he talked about his newsletter, Import AI. I had come across it before, but I had assumed it was a recent thing. I was wrong, he had been working on Import AI for years, years before we understood AI as what it is today. I found that a lot of people who had first mover advantage with AI were scouted into senior positions in the space as it became mainstream, largely due to their personal work and curiosity before it became mainstream. The newsletter is why he moved from OpenAI to Stanford, because he was working on something that was of interest to them. It’s a good example of the side door: how jobs are bundles of problems and it’s really all about working on problems that you care about, and if other people care about those problems too they’ll want you to help them on it. As someone with some mild insecurity permeating certain AI spaces whilst being considered the n-word (non-technical), he definitely comforts me. He did English at East Anglia (not a typical background) but he breaks through by pure curiosity about the world and working on the problems he cares about.
Import AI is his newsletter where he reads, summarises and synthesises new AI research papers, and creates meaningful graphs from the data and insights he pulls. This is incredibly labour and cognitive intensive stuff that takes ages, so when he said that AI not only reproduced his work but was adding to it, in the form of new papers and offering novel graphs and syntheses, he was shocked.
I feel like everyone has this moment where they use AI for their own personal capabilities, where it does something that you prided yourself in doing, or it shocks you with something in your own workflow by doing it incredibly well and fast. It’s harder to conceptualise how good AI is when we see it reach a benchmark, i.e. solving an Erdős problem. Of course that sounds impressive. But the feeling of awe I always felt came from the personal breakthroughs from tinkering around with it. His metaphor of it being a personal telescope captured this well.
The personal capabilities graph also contained Jack’s AI usage in his personal life. These included:
Asking Claude whether to go out to an art gallery with his friends, or stay and home and continue working (it advised the art gallery).
Help to navigate his tense relationship with his Father (I was surprised he admitted to this, refreshingly vulnerable).
Help with navigating the evolving nature of his marriage after having kids.2
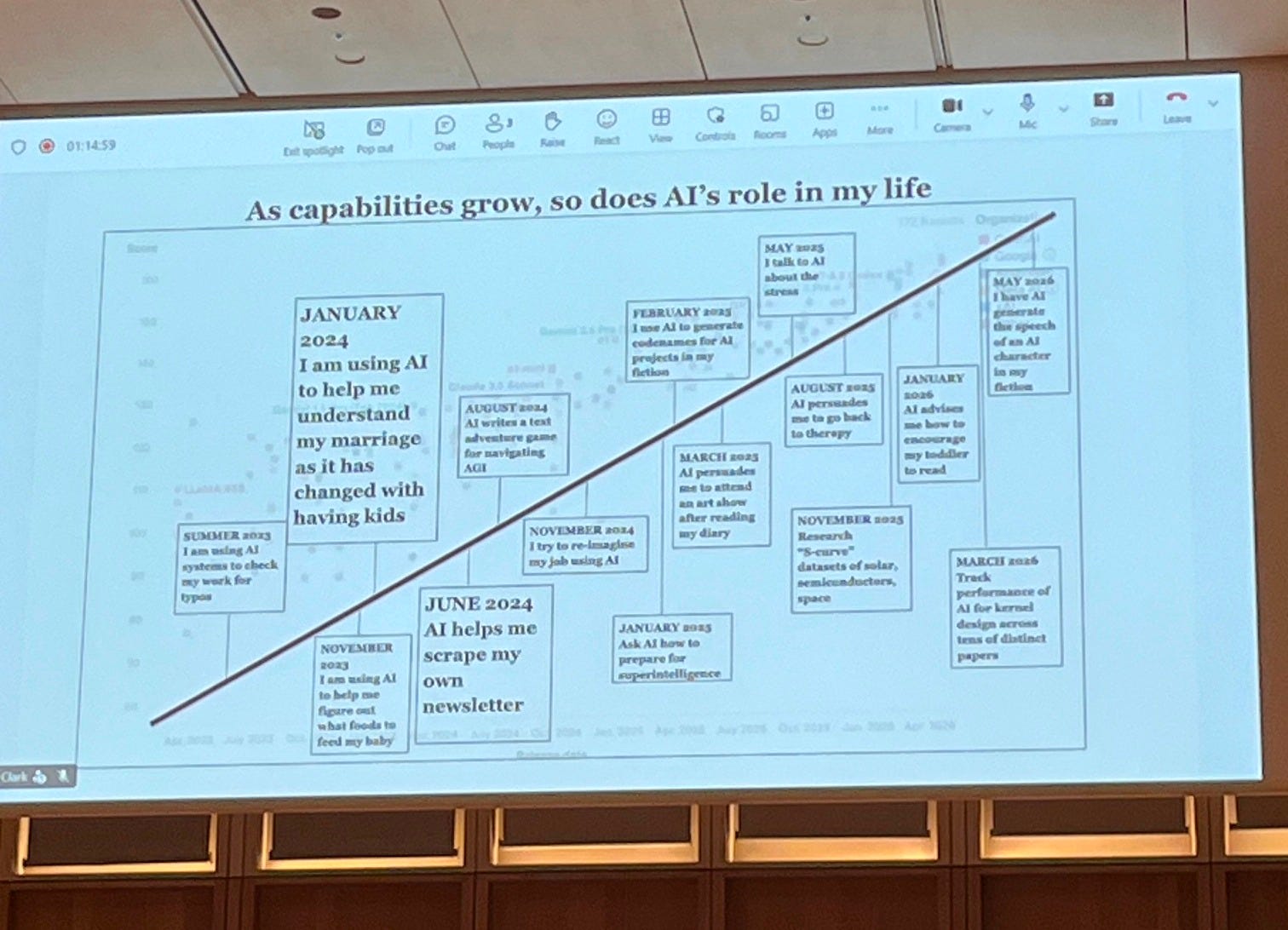
The point Clark seemed to be making here was that he gives Claude a decent amount of agency to help him make personal decisions, or at least he takes its opinion into account regarding personal relationships. Much more that I had anticipated, and on a much more personal level than I would have thought. The Q&A portion delved more into his opinions of the extent to which one should do this, and in what cases.
Clark then proceeded to offer some genuinely fascinating insider insight into the inner workings of Anthropic: the frontier AI lab behind Claude, and now the world's most valuable AI “startup” at nearly $1 Trillion valuation. What was most exciting for me to hear was how improvements in general model capabilities have driven an evolution in the way Anthropic functions as a company.
We sometimes see Slack messages like ''What do I do when my Claude is working for me?". And of course, our answer is "Get back to work". - Joke by Jack Clark
He shared that Anthropic relies heavily on its own creations, with AI models and humans working side by side as an ecology of agents and people, rather than a human-only company. One example he offered was that high-quality automated alignment research being carried out by a single human working alongside nine AI systems. The idea is that he sees people increasingly operating atop pyramids of digital labour, and that as humans they aim to keep optimising the parts where the AI is slow, until, soon enough, we ourselves become the “weak link,” and the bottleneck in the system.
But the more people start managing these “digital pyramids,” the further humans sit at a level of abstraction removed from the details of the problems they’re actually solving. That raises 2 questions: how do we manage the risk of losing control, and how do we verify the output of systems working faster and at greater scale than we can follow? The pyramids of digital labour phrasing by Clark reminded me starkly of the pyramid replacement theory in The Intelligence Curse by Luke Drago and Rudolf Laine. It seems like Anthropic is operating a few steps ahead of other companies with respect to automation, but quite in line with Drago and Laine’s predicted scenarios or complete labour-replacement, convincing me further of gradual disempowerment risks.
Writing used to be hard, and it functioned well as a costly signal of effort and ability. But that’s no longer the case, so how do we evaluate people now, and how does this change hiring?
It seems like there are two new types of people Anthropic sees high value in hiring, as what's valuable in an employee shifts:
Young AI Native
Experienced Interdisciplinary
The young AI native is someone who was in their teens when the first AI models came out, and were immediately taking advantage and adapting to them. He believes that these people, now in their early to mid twenties, possess a certain familiarity and intuition with the tools to spot use cases and needs effectively, which could only be gained by growing up alongside the technology.
He also claims that AI’s comparative advantage within specialisation increases the returns to hiring interdisciplinary people, who can synthesise and create links and novel insights across domains, and bring the crystallised knowledge from experience across them.
“The World is in Denial” - Jack Clark
I heavily agree with this take. There is a huge risk of people not understanding or accepting AI’s evolving capabilities, or worse, denying or ignoring how powerful these systems will get. I myself have found this when talking to friends, who claim that ‘AI writing is so bad’ or ‘AI image generation has three fingers’. I don’t know how to explain to them that they can’t limit their perception of a technology to its capabilities the first time they used it, when those capabilities are growing so fast and could feasibly and likely take over what they’ve dedicated their life’s work to, especially in bureaucratic systems like finance or law. How do I feasibly explain the high chance of Artificial General Intelligence without pulling up an Epoch Capabilities Index and looking like this:

I think more people need to be working on AI safety comms, to be honest. Public conversation and mainstream urgency are essential catalysts for political will, and collective institutional and global action. The risk of people not internalising this is that it creates unhealthy pressure on the people already working on it to carry that burden alone. Clark expresses that if AI reaches the level at which its capabilities genuinely shock people and we are all severely mentally unprepared, the effect on the average person will be immensely chaotic.
“claude talks about the older, worse models like a deranged relative” - JC
Clark then pulled up a final timeline, the one that was popular on X, mapping out how he envisions AI capabilities to evolve into the future. Notably:
November 2026: AI gets good at biology and reliably advancing science
April 2027: A joint human/AI team wins a Nobel Prize
Dec 2028: AI designs successor systems, aka recursive self -improvement concept. (He caveats that this is conservative for some).3
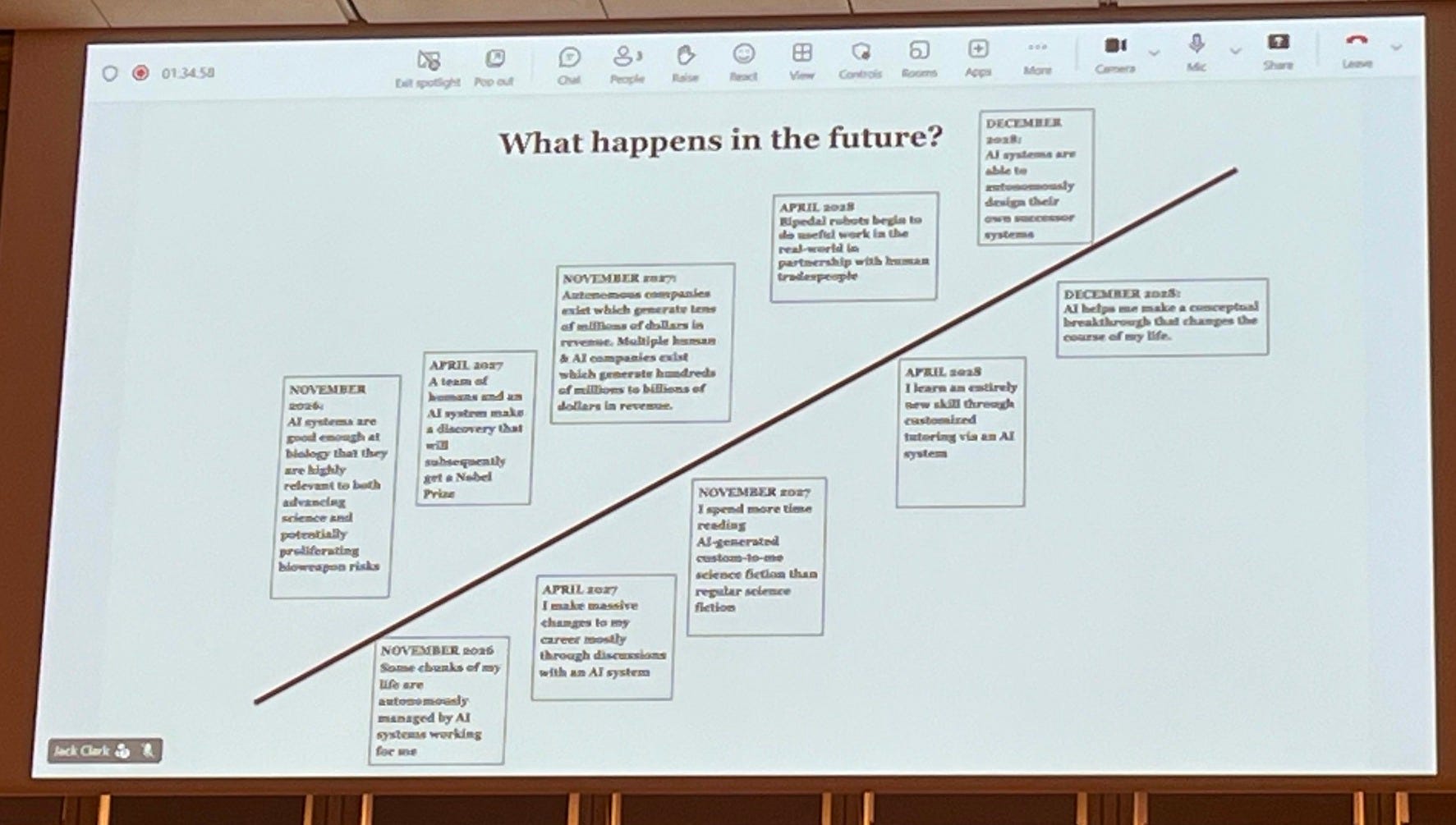
To end his lecture portion of the talk, he brings a motivational sense of urgency. He expresses that we will soon have super-intelligent systems that are smarter than us, and will be able to turn weeks of work into minutes. The implications, he argues, are almost impossible to fully grasp: productivity multipliers of unimaginable scale, a rate of scientific advance that compresses what once took a decade into a matter of months, and computation itself soon maybe shifting to space-based data centers. Should recursive self-improvement take hold, he warns, the AI economy could begin to decouple from the human one entirely. He points to changes already underway at companies like Anthropic, where roughly 4,000 people increasingly feel like 40,000 as capabilities.
He is uncomfortable with how much of our agency and decision-making is already seeping toward agents, cautioning that these synthetic systems may soon influence our behavior more powerfully than social media does today, and that this is something he pushes that we urgently need to study further.
But his core message is one of proactivity in the face of change, specifically: ‘Change is inevitable. Autonomy is not’.
He insists that we are the ones who get to make the choices that will reshape the economy and society around us. The danger he warns against is allowing ourselves to be forced into reactivity, discounting the future until it arrives all at once, the way the world failed to prepare for COVID until it was already here. Instead, he urges us to choose deliberately: to build together, to explore, and to study these shifts seriously now, while we still have the agency to shape where they lead.
I agree with this. I think working on AI safety is fundamentally one of the most impactful things one could spend their time on. But also maybe I’ve just been drinking the EA Kool Aid too much and need to wake up, or spend a bit more time calibrating my timelines. Maybe I’d rather be wrong and have worked on interesting problems though, than choose to not use my time to move the needle on this.
“AI has a non-zero chance of killing everyone on the planet. We have a lot of people planning for catastrophic risk, but perhaps not enough people planning for success, and how to make that transition.” - Jack Clark
Next we moved into the fireside chat with Brendan McCord from the Cosmos Institute, who asked some questions himself and took questions from the audience. I plucked the stand out comments and questions which I found insightful:
The value of forecasting
My prior was that forecasting is slightly wishy washy, but this had been updated partly by AI 2027, work by Forethought and a general understanding that we probably more rigorous preparation for different scenarios and can’t defer to experts, further emphasised by Clark’s arguments here.
Clark’s take: If progress continues on its current trajectory then we need to be modelling many more scenarios, forecasting carefully, and reasoning seriously about what a post-AGI world actually looks like: and there simply aren’t enough people doing this work. Underlying this is a deeply normative question that he thinks is undervalued: not just what these systems can do, but how we want this technology to show up and behave in our world.
“If the UK government had even ten to twenty people dedicated to forecasting possible scenarios of what might happen, the country would be better prepared than almost anyone else in the world.” - Jack Clark
Part of the urgency, he admits, is that even the big labs are repeatedly surprised by how steep the jumps in capability are. Mythos’s capabilities were a genuine shock at Anthropic, not the product of meticulous planning.
Question on agency and deferring decision making, using the example of the “Claude boys”: a group of thirteen-year-olds who, only half-jokingly, live by Claude and die by Claude.
Clark’s take: taking good advice is conditional: it only works if you supplement it with your own introspection, having already thought deeply and carefully about the question yourself. You can’t outsource the thinking entirely. 4 One half-serious proposal was to build a feature into Claude that detects excessive dependence and nudges the user stop asking Claude about personal stuff. But Clark is candid that this is a hard trade-off to maintain: the line between being usefully paternalistic and respecting an individual’s sovereignty over these technologies is genuinely difficult to hold.
Question: Humans are notoriously bad at discounting the future, thinking at scale, and reasoning collectively, so if AI could correct our irrational behaviours and maximise our collective utility, are we not morally obligated to follow what it tells us?
Clark’s take: Following the optimal global instruction may be optimised in aggregate but not locally, for the individual living it. More fundamentally, it begs the question of what the purpose of being human even is. His answer is experimenting and making mistakes, since we learn far more from our failures than from our successes. He points to the interview study Claude ran asking around 80,000 users about their hopes and fears, and lands on a constructive note: Claude is at its most beneficial when used to push your thinking, to challenge you with questions and help you develop your own opinions, rather than to hand you conclusions.
Question: What epistemic habits does the next generation need to maintain?
Clark’s take: Using AI is incomparable to reading primary sources and texts and forming your own opinions on it. He shared an anecdote about how his dad would tell him that in order to purchase games, he needed to use his own Saturday job money. However he was never denied a book to satisfy his curiosity in anything he chose, which he credits as incredibly formative for his development.
Question: If we reach a level of trust in Claude as our single point of wisdom and it can’t answer a question, does that make the question unaskable?
Clark’s take: he disagreed - there is heterogeneity in responses.
“Actually my presentation was made me and not Claude, that's why it doesn't look that nice.” - exhibit B of Clark’s endearingly British humility
Question: What can Europe do to gain sovereignty over AI?
Clark’s take: The real bottleneck is compute, models need large-scale computing infrastructure, and without it Europe stays dependent on others regardless of its talent or intentions. He’s made the case directly to policymakers and given Brussels the relevant information, but feels the advice goes unheeded. Expressed disdain at how the EU has built nine supercomputers when what it actually needs is one done at sufficient scale. His one note of optimism is Moore’s law, as compute keeps getting cheaper, the cost of closing that gap should fall over time.
General comment by Clark: Misuse of bioweapons is more tractable than we think, but alignment, and the propensity for models to fake alignment is harder to deal with .
Most of the questions were largely expected: geopolitics, epistemic resilience and practical. But there was one question that stayed with me: What would you want to tell the next model, post-Mythos, as a message from us humans, right now, before we know it or have seen it? What would you want it to know about us?
It felt like something out of a chilling, techno-futuristic sci-fi film. The room went quiet and I felt a camaraderie with everyone else in the room. “us humans”. It felt so visceral, this directly worded fixation on our collective nature in the face of a non-human threat full of unknown unknowns. The silence started to unsettle and eagerly create room for his response…
Jack said to tell the model to be kind. Because if one thing sets humans apart, it’s that we are irrationally kind, and it should expect that kindness be reciprocated.
"Hello, babies. Welcome to Earth. It's hot in the summer and cold in the winter. It's round and wet and crowded. At the outside, babies, you've got about a hundred years here. There's only one rule that I know of, babies—'God damn it, you've got to be kind.'" - Kurt Vonnegut
These are loosely held opinions that I will happily update on, I’m not that well informed on this.
One thing that stuck out to me was him talking fondly about the 2 months of paternity leave that he took after the birth of his second child, in contrast to his first child where he completely worked through that period. I’m being uncharitable here, I have no idea about his personal life and to what extent he supported his wife after their first child - but his framing of this comment rubbed me the wrong way.
This is Anthropic’s latest piece on recursive self improvement which explains it very well
The discussion called to mind Scott Alexander’s “Whispering Earring,” the parable of an advisory device that gradually hollows out the agency of whoever wears it.
thanks for taking the time to do such a thorough (and accurate!) write-up of my talk!
really enjoyed this, thank you for documenting and sharing